

介绍
这是一个声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。
支持 中文、英文、日语、韩语 4种语言,可在线从麦克风录制声音。
为保证合成效果,建议录制时长5秒到20秒,发音清晰准确,不要存在背景噪声。
英文效果很棒,中文效果还凑合。
项目地址:https://github.com/jianchang512/clone-voice
视频演示:https://nftstorage.link/ipfs/bafybeidk2semsomdo6m23ik6b7ktzpth6wsb72zd4wwuzksue57ys633wy
使用方法
-
右侧[Releases]https://github.com/jianchang512/clone-voice/releases中下载预编译版,适用于window 10/11(已含文字到语音模型,语音到语音模型需单独下载),Mac下请拉取源码自行编译
-
下载后解压到某处,比如 E:/clone-voice 下
-
双击 start.bat ,等待自动打开web窗口,如下
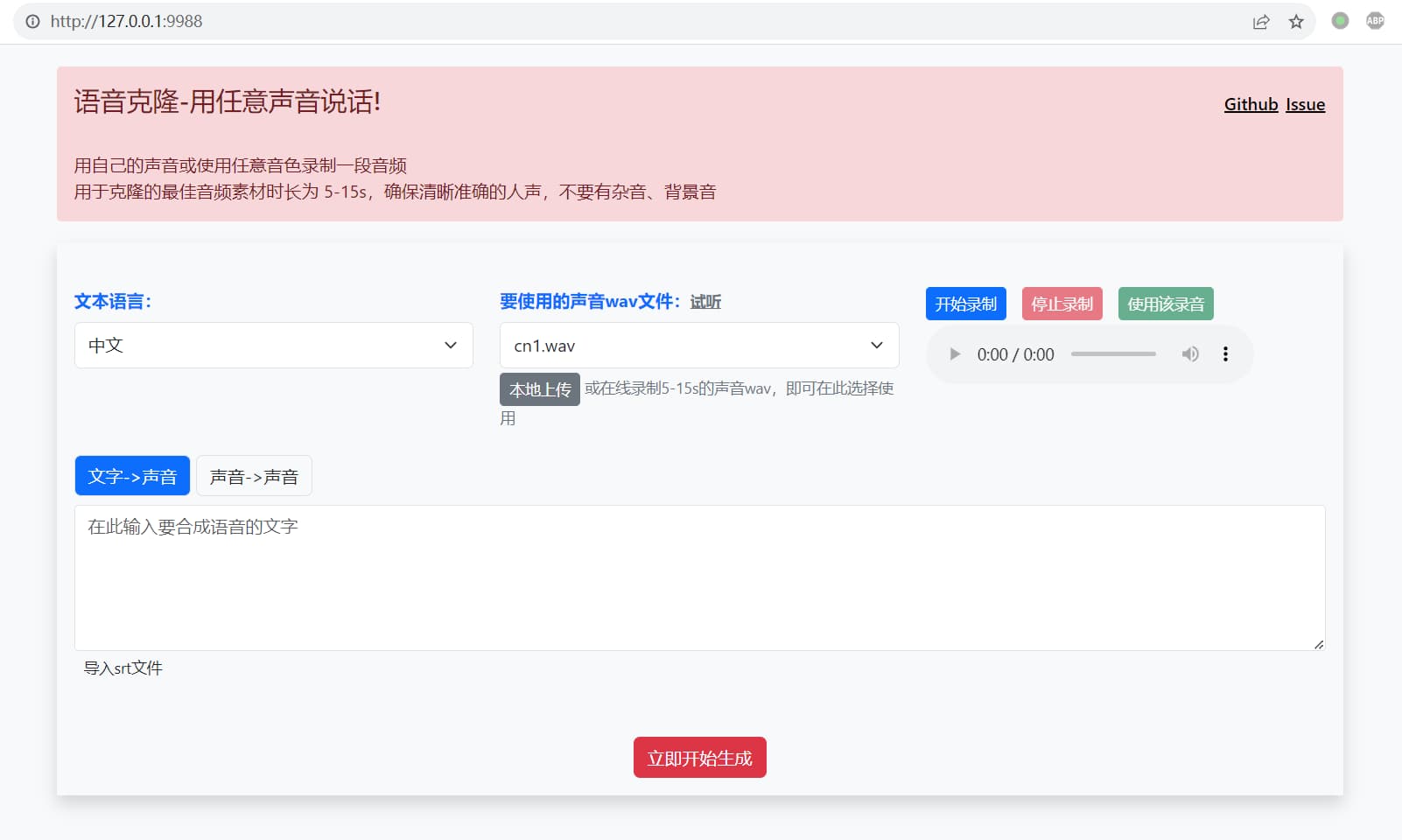
-
转换操作步骤
-
在文本框中输入文字、或导入srt文件,或者选择“声音->声音”,选择要转换的声音wav格式文件
-
然后从“要使用的声音wav文件”下拉框中选择要用的声音,如果没有满意的,也可以点击“本地上传”按钮,选择已录制好的5-20s的wav声音文件。或者点击“开始录制”按钮,在线录制你自己的声音5-20s,录制完成点击使用
-
点击“立即开始生成”按钮,耐心等待完成。
-
-
为减小预编译版体积,预编译版仅支持CPU,只包含“文字到语音(text-to-speech)模型”
如果需要 声音->声音 功能,即上传一个音频文件,然后将该音频转换为使用选定音色的另一个音频,需单独下载语音到语音(speech-to-speech)模型,然后放到和app.exe同级的tts文件夹中,右键“解压到当前文件夹下” 解压
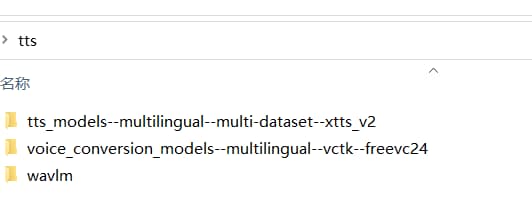
6、如需GPU支持,请拉取源码本地编译
源码部署/以window为例,其他类似
-
要求 python 3.9+
-
创建空目录,比如 E:/clone-voice
-
创建虚拟环境
python -m venv venv -
激活环境
cd venv/scripts,activate,cd ../.. -
安装依赖 CPU版:
pip install -r requirements.txt, GPU版:pip install -r requirements-gpu.txt -
解压 ffmpeg.7z 到项目根目录
-
下载模型 文字到语音(text-to-speech)模型 和 语音到语音(speect-to-speech)模型 到项目目录下的tts文件中,然后解压到当前文件夹
-
启动
python app.py
模型下载
-
语音到语音模型(speech-to-speech)百度网盘下载 链接:https://pan.baidu.com/s/1vIYzxnlmx2_4prahufoEEw?pwd=hgh2 提取码:hgh2 从github下载: https://github.com/jianchang512/clone-voice/releases/tag/v0.0.1 解压
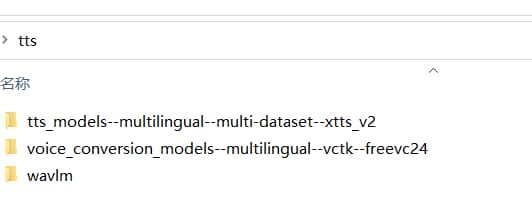
2、文字到语音模型(text-to-speech)百度网盘下载(预编译版已包含该模型) 链接:https://pan.baidu.com/s/1LA3JFIb0MnCgoF0Q1sW5dQ?pwd=5k7c 提取码:5k7c 从github下载: https://github.com/jianchang512/clone-voice/releases/tag/v0.0.1 解压后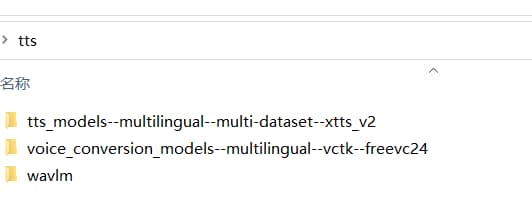
3、预编译版下载(已包含text-t-speech文字到语音模型) 点击右侧 Releases,下载最新版本
注意事项
-
启动后需要冷加载模型,会消耗一些时间,请耐心等待显示出
http://127.0.0.1:9988, 并自动打开浏览器页面后,稍等两三分钟后再进行转换 -
功能有:
文字到语音:即输入文字,用选定的音色生成声音,这个功能预编译已包含模型,开箱即用。 声音到声音:即从本地选择一个音频文件,用选定的音色生成另一个音频文件,为减小预编译版体积,没有包含在内,需要单独下载模型,放在app.exe 同目录下的tts文件夹中,解压到当前文件夹下,解压后会多两个文件夹,`voice_conversion_models--multilingual--vctk--freevc24`和`wavlm`,请确保位置正确
-
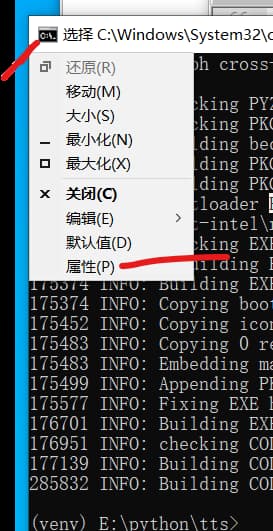
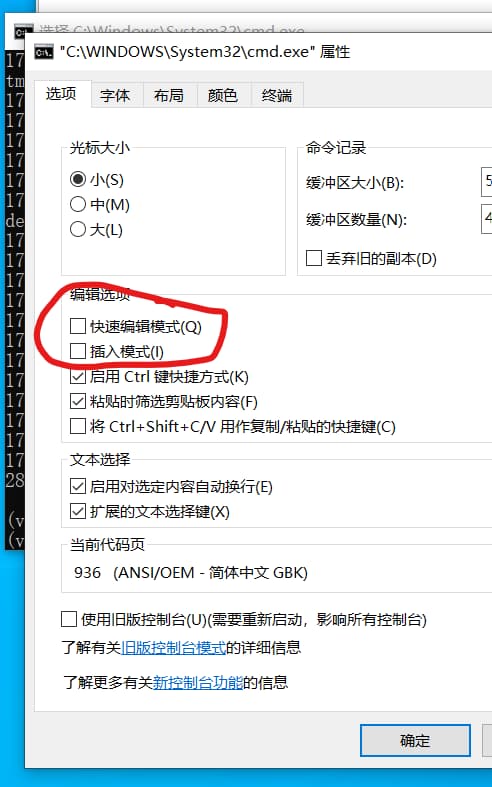
如果打开的cmd窗口很久不动,需要在上面按下回车才继续输出,请在cmd左上角图标上单击,选择“属性”,然后取消“快速编辑”和“插入模式”的复选框
预览图



0 条评论