

欢迎来到Llama中文社区!TA是一个专注于Llama模型在中文方面的优化和上层建设的高级技术社区。 *基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级*。
🚀 高级工程师团队支持:社区有一批专注为大家服务的NLP高级工程师,我们有着强大的技术支持和丰富的经验,为您提供专业的指导和帮助。
🎯 中文优化:致力于在Llama2模型的中文处理方面进行优化,探索适用于中文的最佳实践,以提升其性能和适应性。
💡 创新交流:拥有一支富有创造力和经验的社区成员团队,定期组织线上活动、技术研讨和经验分享,促进成员间的创新交流。
🌐 全球联结:欢迎来自世界各地的开发者加入社区,构建一个开放、多元化的学习和交流平台。
🤝 开放共享:鼓励社区成员开源分享代码和模型,推动合作共赢,共同促进中文NLP技术的发展。
社区活动
🗓️ 线上讲座:邀请行业内专家进行线上讲座,分享Llama2在中文NLP领域的最新技术和应用,探讨前沿研究成果。
💻 项目展示:成员可展示自己在Llama2中文优化方面的项目成果,获得反馈和建议,促进项目协作。
📚 学习资源:社区维护丰富的学习资料库,包括教程、文档和论文解读,为成员提供全面的学习支持。
📝 论文解读:社区成员共同解读与Llama2相关的最新研究论文,深入理解前沿算法和方法。
🎉 主题活动:定期举办各类主题活动,包括挑战赛、黑客马拉松和技术沙龙,让社区成员在轻松愉快的氛围中交流和学习。
🌟 奖励计划:我们设立奖励计划,对社区中积极参与、贡献优秀的成员给予荣誉和奖励,激励更多优秀人才的加入。
📈 技术咨询:我们提供技术咨询服务,解答您在Llama2开发和优化过程中遇到的问题,助您快速攻克难关。
🚀 项目合作:鼓励成员间的项目合作,共同探索Llama2在实际应用中的潜力,打造创新解决方案。
国内Llama2最新下载地址
本仓库中的代码示例主要是基于Hugging Face版本参数进行调用,我们提供了脚本将Meta官网发布的模型参数转换为Hugging Face支持的格式,可以直接通过transformers库进行加载:
-
Llama2-7B官网版本:https://pan.xunlei.com/s/VN_kR2fwuJdG1F3CoF33rwpIA1?pwd=z9kf
-
Llama2-7B-Chat官网版本:https://pan.xunlei.com/s/VN_kQa1_HBvV-X9QVI6jV2kOA1?pwd=xmra
-
Llama2-13B官网版本:https://pan.xunlei.com/s/VN_izibaMDoptluWodzJw4cRA1?pwd=2qqb
-
Llama2-13B-Chat官网版本:https://pan.xunlei.com/s/VN_iyyponyapjIDLXJCNfqy7A1?pwd=t3xw
-
Llama2-7B Hugging Face版本:https://pan.xunlei.com/s/VN_t0dUikZqOwt-5DZWHuMvqA1?pwd=66ep
-
Llama2-7B-Chat Hugging Face版本:https://pan.xunlei.com/s/VN_oaV4BpKFgKLto4KgOhBcaA1?pwd=ufir
-
Llama2-13B Hugging Face版本:https://pan.xunlei.com/s/VN_yT_9G8xNOz0SDWQ7Mb_GZA1?pwd=yvgf
-
Llama2-13B-Chat Hugging Face版本:https://pan.xunlei.com/s/VN_yA-9G34NGL9B79b3OQZZGA1?pwd=xqrg
-
Llama2-70B-Chat Hugging Face版本:https://pan.xunlei.com/s/VNa_vCGzCy3h3N7oeFXs2W1hA1?pwd=uhxh#
-
CodeLlama-7b官网版本:https://pan.baidu.com/s/1cIPzdNywWLvQI7_2QanOEQ?pwd=zfwi
-
CodeLlama-7b-Python官网版本:https://pan.baidu.com/s/1liY8klGoDagYbpw-g-oFag?pwd=i952
-
CodeLlama-7b-Instruct官网版本:https://pan.baidu.com/s/108o9_DT2E_vfSGtOnDCQVw?pwd=zkt9
-
CodeLlama-13b官网版本:https://pan.baidu.com/s/1lLaeHv0XEBv0iiZzI1dpnw?pwd=qn99
-
CodeLlama-13b-Python官网版本:https://pan.baidu.com/s/1OLVfvZS_oqL3oqMKwsI87w?pwd=a78k
-
CodeLlama-13b-Instruct官网版本:https://pan.baidu.com/s/1HyxJl4w8wElgkZRh2ATrXQ?pwd=seg6
-
CodeLlama-34b官网版本:https://pan.baidu.com/s/1vEw0pFgIkctPUN4_5_6pIQ?pwd=q8eu
🔵 Atom大模型
原子大模型Atom由Llama中文社区和原子回声联合打造,在中文大模型评测榜单C-Eval中位居前十(8月21日评测提交时间)。

Atom系列模型包含Atom-7B和Atom-13B,基于Llama2做了中文能力的持续优化。Atom-7B和Atom-7B-Chat目前已完全开源,支持商用,可在仓库获取模型,详情见。Atom大模型针对中文做了以下优化:
大规模的中文数据预训练
原子大模型Atom在Llama2的基础上,采用大规模的中文数据进行持续预训练,包含百科、书籍、博客、新闻、公告、小说、金融数据、法律数据、医疗数据、代码数据、专业论文数据、中文自然语言处理竞赛数据集等,详见。
同时对庞大的数据进行了过滤、打分、去重,筛选出超过1T token的高质量中文数据,持续不断加入训练迭代中。
更高效的中文词表
为了提高中文文本处理的效率,我们针对Llama2模型的词表进行了深度优化。首先,我们基于数百G的中文文本,在该模型词表的基础上扩展词库至65,000个单词。经过测试,我们的改进使得中文编码/解码速度提高了约350%。此外,我们还扩大了中文字符集的覆盖范围,包括所有emoji符号😊。这使得生成带有表情符号的文章更加高效。
自适应上下文扩展
Atom大模型默认支持4K上下文,利用位置插值PI和Neural Tangent Kernel (NTK)方法,经过微调可以将上下文长度扩增到32K。
📝 中文数据
我们通过以下数据来优化Llama2的中文能力:
| 类型 | 描述 |
|---|---|
| 网络数据 | 互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据。 |
| 中文Wikipedia的数据 | |
| 中文悟道开源的200G数据 | |
| Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 | |
| 竞赛数据集 | 近年来中文自然语言处理多任务竞赛数据集,约150个 |
| MNBVC 中清洗出来的部分数据集 |
希望大家如果有较高质量的数据集能够提供给我们,不胜感激!💕💕
⏬ 模型部署
Meta在🤗Hugging Face上提供了所有模型的下载链接:https://huggingface.co/meta-llama
Llama中文社区的中文模型下载链接:https://huggingface.co/FlagAlpha
模型下载
Meta官方Llama2模型
Llama2预训练模型包含7B、13B和70B三个版本。Llama2-Chat模型基于预训练模型进行了监督微调,具备更强的对话能力。
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 预训练 | Llama2-7B | meta-llama/Llama-2-7b-hf | | |
| 预训练 | Llama2-13B | meta-llama/Llama-2-13b-hf | | |
| 预训练 | Llama2-70B | meta-llama/Llama-2-70b-hf | |
| Chat | Llama2-7B-Chat | meta-llama/Llama-2-7b-chat-hf | | |
| Chat | Llama2-13B-Chat | meta-llama/Llama-2-13b-chat-hf | | |
| Chat | Llama2-70B-Chat | meta-llama/Llama-2-70b-chat-hf | | |
基于Llama2的中文微调模型
我们基于中文指令数据集对Llama2-Chat模型进行了微调,使得Llama2模型有着更强的中文对话能力。LoRA参数以及与基础模型合并的参数均已上传至,目前包含7B和13B的模型。
| 类别 | 模型名称 | 🤗模型加载名称 | 基础模型版本 | 下载地址 |
|---|---|---|---|---|
| 合并参数 | Llama2-Chinese-7b-Chat | FlagAlpha/Llama2-Chinese-7b-Chat | meta-llama/Llama-2-7b-chat-hf | |
| 合并参数 | Llama2-Chinese-13b-Chat | FlagAlpha/Llama2-Chinese-13b-Chat | meta-llama/Llama-2-13b-chat-hf | |
| LoRA参数 | Llama2-Chinese-7b-Chat-LoRA | FlagAlpha/Llama2-Chinese-7b-Chat-LoRA | meta-llama/Llama-2-7b-chat-hf | |
| LoRA参数 | Llama2-Chinese-13b-Chat-LoRA | FlagAlpha/Llama2-Chinese-13b-Chat-LoRA | meta-llama/Llama-2-13b-chat-hf |
基于Llama2的中文预训练模型Atom
社区提供预训练版本Atom-7B和基于Atom-7B进行对话微调的模型参数供开放下载,模型参数会持续不断更新,关于模型的进展详见社区官网。
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 预训练 | Atom-7B | FlagAlpha/Atom-7B | | | |
| Chat | Atom-7B-Chat | FlagAlpha/Atom-7B-Chat | | | |
模型调用代码示例
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model = AutoModelForCausalLM.from_pretrained('FlagAlpha/Atom-7B-Chat',device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
FastAPI接口搭建
为了方便通过API方式调用模型,我们提供了脚本用来快速搭建接口,相关测试代码与API参数设置见。
Gradio快速搭建问答平台
基于gradio搭建的问答界面,实现了流式的输出,将下面代码复制到控制台运行,以下代码以Atom-7B模型为例,不同模型只需修改一下代码里的模型名称就好了😊
python examples/chat_gradio.py --model_name_or_path FlagAlpha/Atom-7B-Chat
Docker部署问答接口
详情参见:
第一步:准备docker镜像,通过docker容器启动
git clone https://github.com/LlamaFamily/Llama-Chinese.git cd Llama-Chinese docker build -f docker/Dockerfile -t flagalpha/llama2-chinese:gradio .
第二步:通过docker-compose启动chat_gradio
cd Llama-Chinese/docker docker-compose up -d --build
🤖 模型预训练
虽然Llama2的预训练数据相对于第一代LLaMA扩大了一倍,但是中文预训练数据的比例依然非常少,仅占0.13%,这也导致了原始Llama2的中文能力较弱。为了能够提升模型的中文能力,可以采用微调和预训练两种路径,其中:
-
微调需要的算力资源少,能够快速实现一个中文Llama的雏形。但缺点也显而易见,只能激发基座模型已有的中文能力,由于Llama2的中文训练数据本身较少,所以能够激发的能力也有限,治标不治本。
-
基于大规模中文语料进行预训练,成本高,不仅需要大规模高质量的中文数据,也需要大规模的算力资源。但是优点也显而易见,就是能从模型底层优化中文能力,真正达到治本的效果,从内核为大模型注入强大的中文能力。
我们为社区提供了Llama模型的预训练代码,以及,更多数据可以参考。具体代码和配置如下:
-
模型预训练脚本:
-
预训练实现代码:
-
DeepSpeed
加速:
-
对于单卡训练,可以采用ZeRO-2的方式,参数配置见
-
对于多卡训练,可以采用ZeRO-3的方式,参数配置见
-
-
训练效果度量指标:
💡 模型微调
本仓库中同时提供了LoRA微调和全量参数微调代码,关于LoRA的详细介绍可以参考论文“”以及微软Github仓库。
Step1: 环境准备
根据安装对应的环境依赖。
Step2: 数据准备
在data目录下提供了一份用于模型sft的数据样例:
-
训练数据:
-
验证数据:
每个csv文件中包含一列“text”,每一行为一个训练样例,每个训练样例按照以下格式将问题和答案组织为模型输入,您可以按照以下格式自定义训练和验证数据集:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案
例如,
<s>Human: 用一句话描述地球为什么是独一无二的。</s><s>Assistant: 因为地球是目前为止唯一已知存在生命的行星。</s>
Step3: 微调脚本
LoRA微调
LoRA微调脚本见:,关于LoRA微调的具体实现代码见,单机多卡的微调可以通过修改脚本中的--include localhost:0来实现。
全量参数微调
全量参数微调脚本见:,关于全量参数微调的具体实现代码见。
Step4: 加载微调模型
LoRA微调
基于LoRA微调的模型参数见:,LoRA参数需要和基础模型参数结合使用。
通过加载预训练模型参数和微调模型参数,以下示例代码中,base_model_name_or_path为预训练模型参数保存路径,finetune_model_path为微调模型参数保存路径。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel,PeftConfig
# 例如: finetune_model_path='FlagAlpha/Llama2-Chinese-7b-Chat-LoRA'
finetune_model_path=''
config = PeftConfig.from_pretrained(finetune_model_path)
# 例如: base_model_name_or_path='meta-llama/Llama-2-7b-chat'
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path,device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model = PeftModel.from_pretrained(model, finetune_model_path, device_map={"": 0})
model =model.eval()
input_ids = tokenizer(['<s>Human: 介绍一下北京\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
全量参数微调
对于全量参数微调的模型,调用方式同,只需要修改其中的模型名称或者保存路径即可。
🍄 模型量化
我们对中文微调的模型参数进行了量化,方便以更少的计算资源运行。目前已经在上传了13B中文微调模型的4bit压缩版本,具体调用方式如下:
环境准备:
pip install git+https://github.com/PanQiWei/AutoGPTQ.git
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized('FlagAlpha/Llama2-Chinese-13b-Chat-4bit', device="cuda:0")
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Llama2-Chinese-13b-Chat-4bit',use_fast=False)
input_ids = tokenizer(['<s>Human: 怎么登上火星\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
🚀 推理加速
随着大模型参数规模的不断增长,在有限的算力资源下,提升模型的推理速度逐渐变为一个重要的研究方向。常用的推理加速框架包含 lmdeploy、FasterTransformer、vLLM和JittorLLMs 等。
TensorRT-LLM
由NVIDIA开发,高性能推理框架
详细的推理文档见:
vLLM
由加州大学伯克利分校开发,核心技术是PageAttention,吞吐量比HuggingFace Transformers高出24倍。相较与FasterTrainsformer,vLLM更加的简单易用,不需要额外进行模型的转换,支持fp16推理。
详细的推理文档见:
JittorLLMs
由非十科技领衔,与清华大学可视媒体研究中心合作研发,通过动态swap机制大幅降低硬件配置要求(减少80%),并且Jittor框架通过零拷贝技术,大模型加载相比Pytorch开销降低40%,同时,通过元算子自动编译优化,计算性能提升20%以上。
详细的推理文档见:
lmdeploy
由上海人工智能实验室开发,推理使用 C++/CUDA,对外提供 python/gRPC/http 接口和 WebUI 界面,支持 tensor parallel 分布式推理、支持 fp16/weight int4/kv cache int8 量化。
详细的推理文档见:
🥇 模型评测
为了能够更加清晰地了解Llama2模型的中文问答能力,我们筛选了一些具有代表性的中文问题,对Llama2模型进行提问。我们测试的模型包含Meta公开的Llama2-7B-Chat和Llama2-13B-Chat两个版本,没有做任何微调和训练。测试问题筛选自,共95个测试问题,包含:通用知识、语言理解、创作能力、逻辑推理、代码编程、工作技能、使用工具、人格特征八个大的类别。
测试中使用的Prompt如下,例如对于问题“列出5种可以改善睡眠质量的方法”:
[INST] <<SYS>> You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. The answer always been translate into Chinese language. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. The answer always been translate into Chinese language. <</SYS>> 列出5种可以改善睡眠质量的方法 [/INST]
Llama2-7B-Chat的测试结果见,Llama2-13B-Chat的测试结果见。
通过测试我们发现,Meta原始的Llama2 Chat模型对于中文问答的对齐效果一般,大部分情况下都不能给出中文回答,或者是中英文混杂的形式。因此,基于中文数据对Llama2模型进行训练和微调十分必要,我们的中文版Llama2模型也已经在训练中,近期将对社区开放。
💪 外延能力
除了持续增强大模型内在的知识储备、通用理解、逻辑推理和想象能力等,未来,我们也会不断丰富大模型的外延能力,例如知识库检索、计算工具、WolframAlpha、操作软件等。 我们首先集成了LangChain框架,可以更方便地基于Llama2开发文档检索、问答机器人和智能体应用等,关于LangChain的更多介绍参见。
LangChain
针对LangChain框架封装的Llama2 LLM类见,简单的调用代码示例如下:
from llama2_for_langchain import Llama2
# 这里以调用FlagAlpha/Atom-7B-Chat为例
llm = Llama2(model_name_or_path='FlagAlpha/Atom-7B-Chat')
while True:
human_input = input("Human: ")
response = llm(human_input)
print(f"Llama2: {response}")
🐞 代码模型
Meta官方在2023年8月24日发布了Code Llama,基于代码数据对Llama2进行了微调,提供三个不同功能的版本:基础模型(Code Llama)、Python专用模型(Code Llama – Python)和指令跟随模型(Code Llama – Instruct),包含7B、13B、34B三种不同参数规模。不同模型能力区别如下表所示:
| 模型类别 | 模型名称 | 代码续写 | 代码填充 | 指令编程 |
|---|---|---|---|---|
| Code Llama | CodeLlama-7b | ✅ | ✅ | ❌ |
| CodeLlama-13b | ✅ | ✅ | ❌ | |
| CodeLlama-34b | ✅ | ❌ | ❌ | |
| Code Llama – Python | CodeLlama-7b-Python | ✅ | ❌ | ❌ |
| CodeLlama-13b-Python | ✅ | ❌ | ❌ | |
| CodeLlama-34b-Python | ✅ | ❌ | ❌ | |
| Code Llama – Instruct | CodeLlama-7b-Instruct | ❌ | ✅ | ✅ |
| CodeLlama-13b-Instruct | ❌ | ✅ | ✅ | |
| CodeLlama-34b-Instruct | ❌ | ❌ | ✅ |
我们提供了Code Llama的以及在线体验地址,关于Code Llama的详细信息可以参考官方Github仓库。
📖 学习资料
Meta官方对于的介绍
自从Meta公司发布第一代LLaMA模型以来,羊驼模型家族繁荣发展。近期Meta发布了Llama2版本,开源可商用,在模型和效果上有了重大更新。Llama2总共公布了7B、13B和70B三种参数大小的模型。相比于LLaMA,Llama2的训练数据达到了2万亿token,上下文长度也由之前的2048升级到4096,可以理解和生成更长的文本。Llama2 Chat模型基于100万人类标记数据微调得到,在英文对话上达到了接近ChatGPT的效果。
Llama相关论文
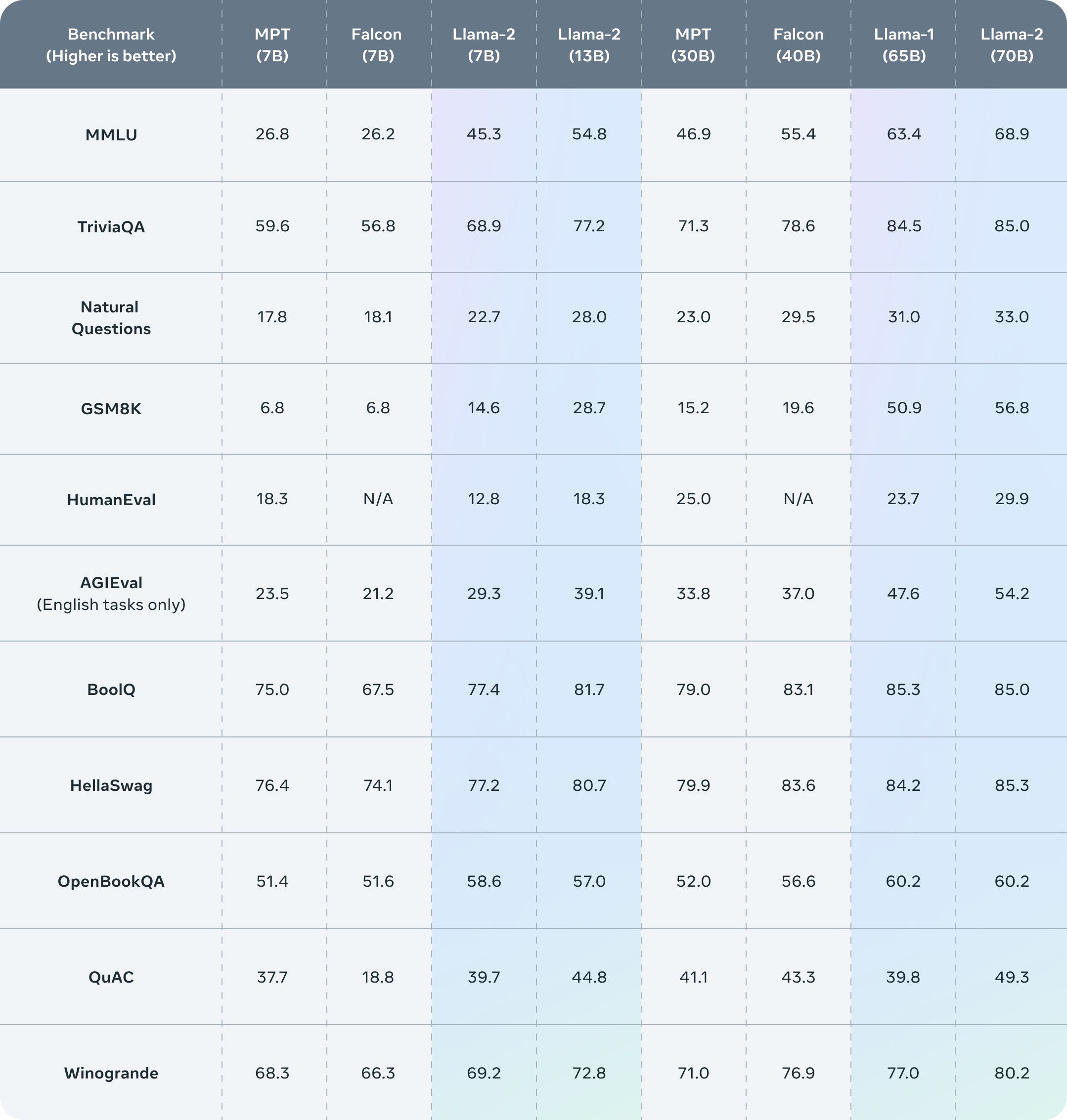
Llama2的评测结果
0 条评论